Hexo + GitHub Pages + NexT 搭建个人博客
算是第一篇博客🥰,总结一下今天搭建博客的过程。
1. 安装 Hexo
按官方文档来就完事了。
遇到一个问题,只有全局安装 Hexo-cli 才能直接用 hexo 命令,否则就得带上 npx ?
TBD…
hexo 本地运行时并不具备热更新机制,甚至有的还需要先 hexo clean 把之前的缓存删了才会看到修改生效。
hexo 中的三种 layout 分别为 post, draft, page,这里的 page 对应的是一个二级路由,也就是列出的几个菜单栏,像分类、标签之类的,所以要创建多个菜单栏的话,先 new 一个 Page,再去主题的配置文件中的 menu 添加这一项就行了,因为主题才是渲染页面的核心。
hexo 图片不显示?
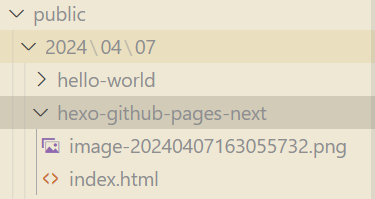
每篇博客的静态资源不隔离显然是很乱的,为此 hexo 配置文件中有一个选项 post_asset_folder ,开启后创建博客时会在同级目录创建一个同名文件夹,里面存放该博客的静态资源。按道理按照相对路径就没问题。
但是 hexo 在 build 出最终的网页文件时,文件位置发生了变化,如下图所示。而将 md 文件中的图片转为 img 标签时,src 属性没弄对,导致图片无法显示。
解决办法:
在 _config.yml 中添加以下配置,而图片路径只用写文件名就行,唯一缺点就是在构建完成之前图片仍然不可见。
2
3
prependRoot: true
postAsset: true不管是装插件,还是加配置,只要路径对了就行。
2. 配置 Github Pages
建库 blog,或者直接就用 username.github.io 这个库,区别就是最后生成的页面 url 是否要带上库名。
修改仓库设置。
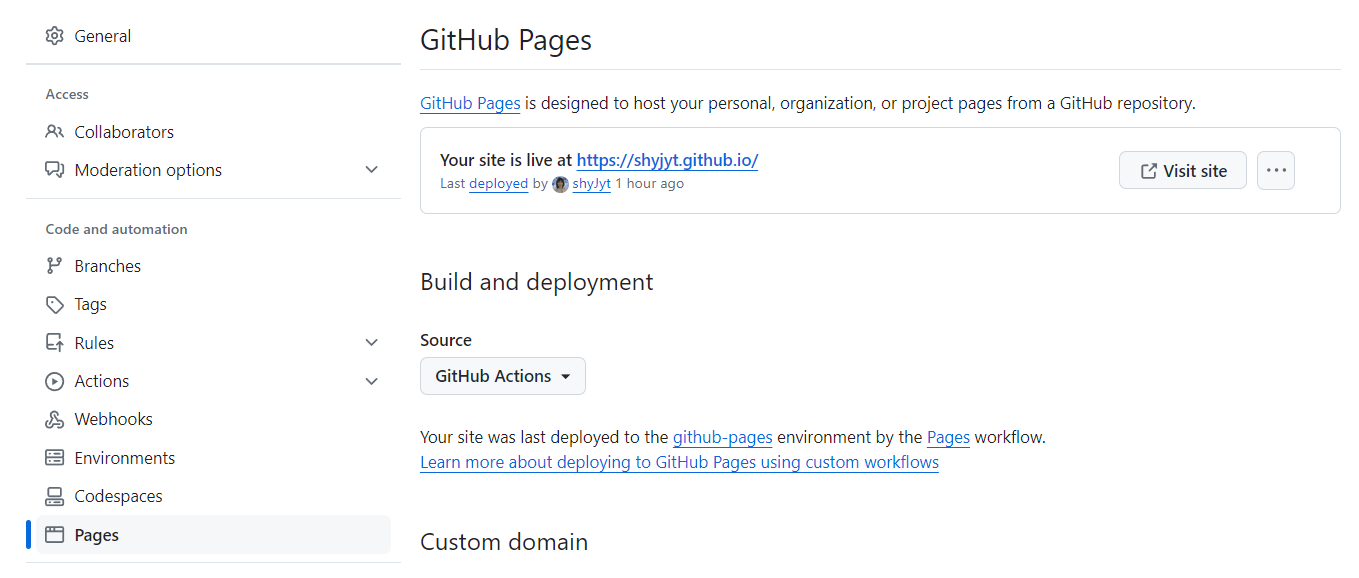
编写 .github/workflows/pages.yml,一个自动化部署的脚本,文档有介绍,本质就是自动完成 build ,将生成的 public 文件夹部署上去,至于是自己的服务器还是 github pages 就随便了。
类似地,前端自动化部署流程也是差不多的,脚本也相对更简单。
3. 配置 NexT 主题
区分 _config.yml 和 _config.theme-name.yml ,两者分别为 hexo 和主题的配置文件。
Hexo 带个默认主题,其他的可以通过 git 和 npm 两种方式获取,主要介绍 npm.
通过 npm 下载下来后,主题的主体部分在 node_modules 中,包括默认的配置文件以及静态文件。NexT 的官方推荐不要去修改,而是单独在根目录创建一个一模一样的配置文件,再修改新创建的配置文件来实现定制。
据观察,主题配置文件会扫描根目录的 source 文件夹和主题包里面的 source 文件夹,且将其作为相对路径的起点,观察一些图片图标的路径就明白了,至于是否会覆盖还没试过。
最后在 _config.yml 中修改 theme 属性就可以了。
4. 杂项
Markdown 不能像 word 将标题作为列表项?这样如果要手动标号的话,后续修改就很麻烦。
感觉中英文切换以及空格很麻烦,以后或许尝试全英文。
文件名怎么这么难取?😵💫