Import
几个基本概念
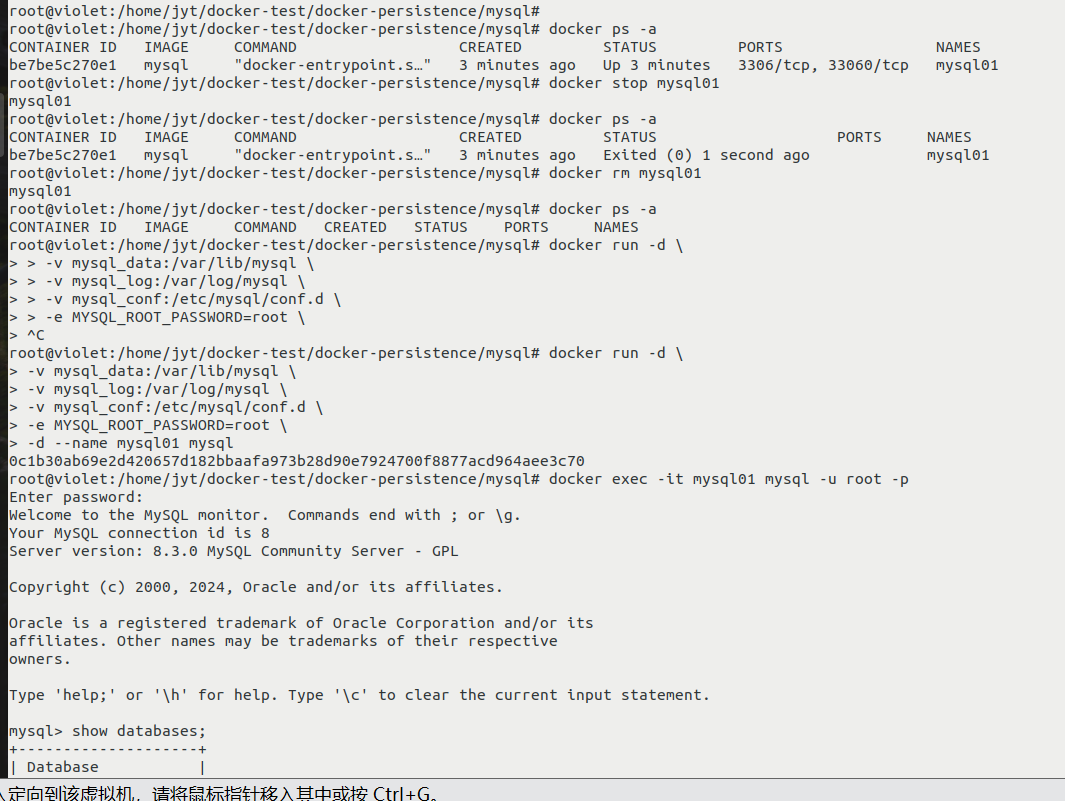
模块
不被直接执行的 py 文件, __name__ 为其包名和模块名拼成。
包含可执行语句及函数定义。这些语句用于初始化模块,仅在 import 语句第一次遇到模块名时执行。
脚本
直接执行的 py 文件,__name__ 为 __main__,也叫主模块。
包
包含 __init__.py 的文件夹
引入
Python 解释器在导入模块时遵循以下搜索顺序,其实也就是 sys.path 的初始值。
被命令行直接运行的脚本所在的目录 或 未指定文件时的当前目录
未指定文件的情况:python -m module,即以模块方式运行指定 module
环境变量 PYTHONPATH 中指定的路径列表中搜索(除了标准库之外的额外搜索目录)
标准库
可以通过修改 sys.path 值来添加搜索路径,但要注意若要添加相对路径,则是相对工作目录的,因为这里的相对是基于文件系统的。
绝对引入
由包名和模块名共同组成,包也应当在可被搜索的范围内。
相对引入
相对导入基于当前模块名,不能通过此方式引入高于顶层包的包。因为主模块名永远是 __main__ ,换句话说,主模块所在文件夹不被视为范围内的包(高于顶层包),主模块同目录下的模块也视为顶层模块(__name__ 仅包含文件名,不包含包名),主模块同级的包被视为顶层包,所以如果一个模块会作为顶级模块(自己或同目录模块被直接执行),那么该模块的导入语句必须始终使用绝对导入。
其他
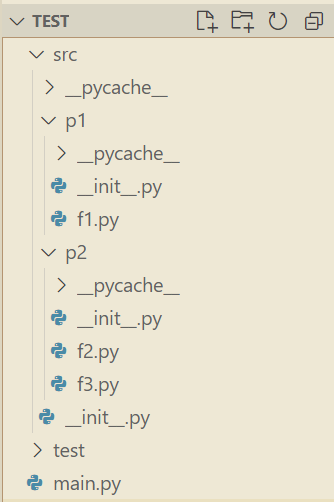
想要在包内部全部使用相对引用,只有执行脚本 main.py 使用绝对引用,以下是个可行的结构,关键在于 main.py 并不在 src 内部,整个 src 被视为顶层包。